






 Microsmeta Podcast
Microsmeta Podcast Feed Atom 0.3
Feed Atom 0.3 Visite guidate a Roma
Visite guidate a Roma








 Think different!
Think different!











\\ Home Page : Articolo
HANNO SUPPORTATO DIGITAL WORLDS INVIANDO PRODOTTI DA RECENSIRE
 |
|
|
 |
|
Federated Learning e Privacy-Preserving AI: addestrare algoritmi senza centralizzare i dati
Di Alex (del 20/02/2026 @ 10:00:00, in Intelligenza Artificiale, letto 378 volte)
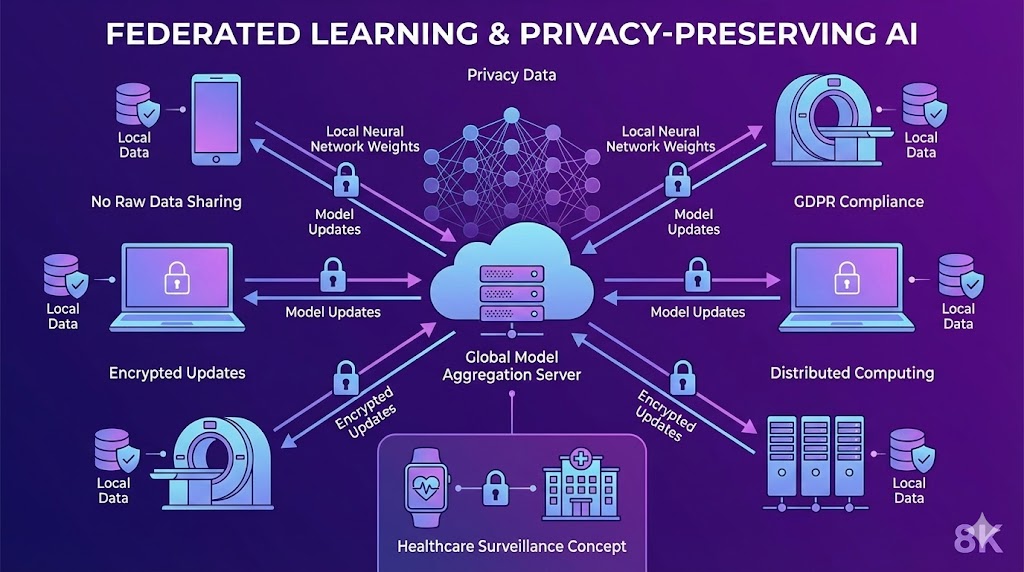
Federated Learning rete distribuita dispositivi smartphone server centrale aggiornamenti pesi neurali privacy dati locali videosorveglianza sanità GDPR
Il Federated Learning addestra algoritmi di IA su dataset distribuiti senza centralizzare i dati grezzi. I modelli imparano localmente sui dispositivi e condividono solo gli aggiornamenti dei pesi neurali. Promettente per videosorveglianza intelligente e sanità, dove la privacy è requisito legale e morale. LEGGI TUTTO L'ARTICOLO
Il problema della centralizzazione dei dati nel machine learning classico
L'addestramento tradizionale di modelli di intelligenza artificiale, in particolare di reti neurali profonde, richiede grandi quantità di dati raccolti e centralizzati in server dove algoritmi di ottimizzazione (come la discesa del gradiente stocastica) aggiornano iterativamente i parametri del modello. Questo approccio centralizzato funziona bene quando i dati possono essere legalmente ed eticamente raccolti in un unico luogo: dataset pubblici come ImageNet per il riconoscimento visivo, corpus linguistici per i modelli di linguaggio naturale. Ma diventa problematico o impossibile in contesti dove i dati sono sensibili, regolamentati o distribuiti per natura. Esempi includono: cartelle cliniche di pazienti distribuite tra ospedali che non possono condividere dati grezzi per vincoli di privacy (GDPR, HIPAA), video di sorveglianza registrati da telecamere private che non devono essere caricati su server centrali, dati finanziari personali custoditi dalle banche che devono rimanere locali. In tutti questi casi, il paradigma centralizzato si scontra con vincoli legali, etici o pratici insuperabili.
Il Federated Learning: apprendimento decentralizzato e collaborativo
Il Federated Learning (apprendimento federato) è un paradigma di addestramento distribuito proposto per la prima volta da ricercatori di Google nel 2016, progettato esplicitamente per risolvere il problema della centralizzazione. Invece di spostare i dati verso il modello, il Federated Learning sposta il modello verso i dati. Il processo funziona così: un server centrale inizializza un modello globale con parametri casuali e lo invia a tutti i dispositivi partecipanti (smartphone, computer ospedalieri, telecamere di sorveglianza). Ogni dispositivo addestra localmente il modello sui propri dati senza mai condividerli, producendo un aggiornamento dei parametri (gradiente o pesi modificati). Gli aggiornamenti vengono inviati al server centrale che li aggrega (tipicamente tramite media pesata) per produrre una nuova versione del modello globale. Il nuovo modello viene redistribuito ai dispositivi e il ciclo si ripete. Cruciale: i dati grezzi non lasciano mai i dispositivi locali. Solo i parametri del modello vengono scambiati.
Privacy differenziale e crittografia omomorfica: proteggere gli aggiornamenti
Anche se i dati grezzi non vengono condivisi, gli aggiornamenti dei parametri possono potenzialmente rivelare informazioni sensibili attraverso attacchi di inferenza sofisticati. Per mitigare questo rischio, il Federated Learning è spesso combinato con tecniche di privacy-preserving come la privacy differenziale e la crittografia omomorfica. La privacy differenziale aggiunge rumore controllato agli aggiornamenti dei parametri prima della trasmissione, garantendo che nessun singolo record nel dataset locale possa essere ricostruito analizzando gli aggiornamenti. La quantità di rumore è calibrata per bilanciare privacy e accuratezza: più rumore significa più privacy ma meno accuratezza del modello. La crittografia omomorfica permette di eseguire operazioni matematiche (somme, moltiplicazioni) su dati crittografati senza decrittarli: il server può aggregare gli aggiornamenti crittografati senza mai vedere i valori in chiaro. Questi metodi aumentano significativamente il costo computazionale ma rendono il Federated Learning adatto anche ai contesti più sensibili.
Applicazioni pratiche: sanità, finanza e videosorveglianza
Nel settore sanitario, il Federated Learning permette di addestrare modelli diagnostici su dati di pazienti distribuiti tra ospedali diversi senza violare le normative sulla privacy. Un esempio reale: nel 2020, un consorzio di 20 ospedali europei utilizzò Federated Learning per addestrare un modello di riconoscimento di tumori cerebrali su scansioni MRI, raggiungendo accuratezza paragonabile a modelli addestrati centralmente ma senza mai condividere le immagini dei pazienti. Nella finanza, banche e istituti di credito possono collaborare per rilevare frodi senza condividere transazioni sensibili. Nella videosorveglianza intelligente, telecamere distribuite in una città possono addestrare modelli di riconoscimento di comportamenti anomali (cadute di persone anziane, incidenti stradali) localmente, inviando solo gli aggiornamenti dei modelli al coordinatore cittadino. Google utilizza Federated Learning per migliorare la tastiera predittiva Gboard su Android: il modello impara dai testi digitati dagli utenti sui loro smartphone senza mai inviare a Google ciò che gli utenti scrivono.
Sfide tecniche: eterogeneità dei dati e comunicazione inefficiente
Il Federated Learning non è privo di sfide. La prima è l'eterogeneità dei dati: i dataset locali possono essere non identicamente distribuiti (non-IID), cioè i dati su uno smartphone possono essere radicalmente diversi da quelli su un altro. Questo causa divergenza durante l'addestramento: il modello globale aggregato può performare male su dispositivi con distribuzioni locali molto diverse dalla media. Soluzioni includono algoritmi di aggregazione più sofisticati (FedProx, FedAvg con momentum) e clustering dei dispositivi per omogeneità. La seconda sfida è la comunicazione: trasmettere aggiornamenti dei parametri di reti neurali profonde (milioni o miliardi di parametri) da migliaia di dispositivi al server può saturare la larghezza di banda. Tecniche di compressione dei gradienti, quantizzazione e comunicazione sparsa riducono il volume di dati trasmessi, ma a costo di leggera perdita di accuratezza.
Implicazioni etiche e legali: GDPR, AI Act e futuro della privacy
Il Federated Learning si allinea perfettamente con i principi del GDPR europeo, che richiede minimizzazione dei dati e privacy by design. L'AI Act dell'Unione Europea, entrato in vigore nel 2024, classifica i sistemi di IA in base al rischio e impone requisiti stringenti per sistemi ad alto rischio usati in sanità, giustizia e infrastrutture critiche. Il Federated Learning può facilitare la conformità permettendo di addestrare modelli accurati senza violare la privacy. Tuttavia, non è una soluzione magica: attacchi di avvelenamento del modello (model poisoning), dove partecipanti malevoli inviano aggiornamenti progettati per degradare il modello, rimangono una minaccia. Meccanismi di validazione degli aggiornamenti e detection di anomalie sono necessari. Il dibattito etico si concentra anche sulla trasparenza: chi controlla il modello globale? Come si garantisce che non sia discriminatorio se i dati locali riflettono pregiudizi storici? Queste domande non hanno risposte tecniche semplici.
Il Federated Learning rappresenta un cambio di paradigma filosofico oltre che tecnico. Invece di chiedere alle persone di fidarsi di un'entità centrale con i loro dati, costruisce fiducia attraverso l'architettura: i dati non si muovono, l'intelligenza si muove. È una risposta tecnologica a una domanda etica: possiamo costruire intelligenze artificiali potenti senza sacrificare la privacy individuale? La risposta sembra essere sì, ma a costo di complessità computazionale e comunicativa significativa. Tuttavia, in un'epoca in cui la privacy è diventata un bene scarso e prezioso, quel costo sembra sempre più giustificato. Il futuro dell'IA potrebbe non essere nei data center centralizzati, ma nelle reti distribuite di dispositivi che imparano insieme senza mai tradire la fiducia di chi li usa.
 Articolo
Articolo  Storico
Storico Stampa
StampaNessun commento trovato.
Disclaimer
L'indirizzo IP del mittente viene registrato, in ogni caso si raccomanda la buona educazione.
L'indirizzo IP del mittente viene registrato, in ogni caso si raccomanda la buona educazione.