Rappresentazione artistica di un cervello digitale e circuiti neurali che si fondono, simbolo dell'IA generativa.
L'umanità è alla soglia di una rivoluzione guidata dall'Intelligenza Artificiale Generativa (GenAI). Questa tecnologia non si limita ad analizzare dati, ma crea nuova conoscenza e simula il ragionamento umano, segnando il passaggio dalla logica deterministica alla computazione probabilistica. Una guida per comprendere il "pensiero" di ChatGPT, Claude e Gemini. LEGGI TUTTO L'ARTICOLO
🎧 Ascolta questo articolo
Genesi storica: l'odissea dai simboli alle reti neurali
La comprensione profonda delle moderne IA generative richiede un viaggio attraverso la storia della computazione. Le capacità apparentemente miracolose di modelli come GPT-4 sono il culmine di decenni di tentativi, fallimenti e intuizioni teoriche.
Le radici: Turing e l'era simbolica (1940-1960)
Tutto inizia con Alan Turing e il suo "Imitation Game" (Test di Turing) del 1950, che spostò il dibattito da "le macchine possono pensare?" a "le macchine possono imitare il comportamento intelligente?". Il campo dell'IA nacque ufficialmente nel 1956 al Dartmouth College. L'approccio dominante era l'IA Simbolica (GOFAI), che cercava di codificare l'intelligenza attraverso regole logiche esplicite. L'esempio celebre è ELIZA, uno psicoterapeuta simulato che, nonostante la sua estrema semplicità, ingannò molti utenti, dimostrando l'"Effetto ELIZA".
Gli inverni dell'IA e l'ascesa del connessionismo (1970-2000)
L'IA simbolica fallì nel gestire l'ambiguità del mondo reale, portando al primo "Inverno dell'IA". Nel frattempo, emergeva l'approccio connessionista, ispirato alla neurobiologia: reti di neuroni artificiali che apprendono dai dati. Negli anni '80, la riscoperta dell'algoritmo di Backpropagation permise di addestrare reti neurali multistrato. Tra il 1980 e il 2010, due innovazioni furono cruciali:
RNN e LSTM: Reti progettate per elaborare sequenze (come il testo), introducendo una forma di memoria per il contesto.
Aumento della potenza di calcolo: La Legge di Moore e l'avvento delle GPU fornirono la potenza necessaria per il Deep Learning su vasti dataset.
La svolta moderna: dalle GAN ai Transformer (2014-2017)
Nel 2014, le GAN (Generative Adversarial Networks) rivoluzionarono la generazione di immagini. Il punto di svolta per il testo arrivò nel 2017 con il paper "Attention Is All You Need", che introdusse l'architettura Transformer. Abbandonando la lenta processazione sequenziale delle RNN, il Transformer utilizzava un meccanismo di "Self-Attention" completamente parallelizzabile, permettendo di addestrare modelli su quantità di dati senza precedenti. Da qui nacquero BERT e il primo GPT di OpenAI, inaugurando l'era dei Large Language Models (LLM).
Il motore semantico: come "pensa" un modello generativo
Al livello fondamentale, un LLM è un motore statistico di predizione. Non "sa" nulla in senso biologico, ma calcola probabilità basandosi sui miliardi di esempi di testo visti in addestramento.
Il principio base: la predizione del prossimo token (Next Token Prediction)
Per completare la frase "Il gatto dorme sul...", il modello analizza la sequenza e calcola la probabilità statistica di ogni possibile parola successiva (token), come "divano", "tappeto" o "letto". Seleziona un token in base a queste probabilità, lo aggiunge alla frase e ripete il processo (inferenza autoregressiva).
Tokenizzazione: tradurre le parole in numeri
Il testo viene spezzato in unità fondamentali chiamate token (parole intere, parti di parole, caratteri). Ogni token è convertito in un ID numerico univoco, permettendo alla rete di lavorare solo con numeri.
Embedding: lo spazio semantico multidimensionale
I token numerici sono proiettati in uno spazio vettoriale ad alta dimensionalità. In questo iper-spazio, ogni concetto ha una posizione (vettore) che cattura relazioni semantiche. Operazioni algebriche su questi vettori possono riflettere analogie, ad esempio: Vettore("Re") - Vettore("Uomo") + Vettore("Donna") ≈ Vettore("Regina").
Temperatura e creatività
Il parametro "Temperatura" controlla la casualità delle risposte. Una temperatura bassa (es. 0.2) fa sì che il modello scelga quasi sempre i token più probabili, portando a risposte deterministiche e fattuali. Una temperatura alta (es. 0.8) introduce più variabilità, permettendo scelte creative ma meno prevedibili.
L'architettura Transformer: il cuore pulsante della rivoluzione
Il meccanismo rivoluzionario del Transformer è la Self-Attention (Auto-Attenzione).
L'analisi del contesto e l'analogia del cocktail party
Come il cervello umano può focalizzarsi su una voce in una stanza rumorosa, la Self-Attention permette a ogni parola di una frase di "guardare" a tutte le altre parole simultaneamente per capire quanto sono rilevanti per il proprio significato, indipendentemente dalla distanza. Questo risolve il problema della dipendenza a lungo termine che affliggeva le RNN.
Il meccanismo tecnico: Query, Key e Value
Per ogni token, il Transformer crea tre vettori:
Query (Q): Rappresenta ciò che il token corrente sta cercando.
Key (K): Rappresenta l'identità di ciascun token.
Value (V): Contiene l'informazione semantica del token.
Il modello calcola l'affinità (prodotto scalare) tra la Query di un token e le Key di tutti gli altri. Se l'affinità è alta, il token "assorbe" una grande porzione del Value del token rilevante. Questo processo avviene in parallelo attraverso molteplici "teste di attenzione".
Positional encoding: l'ordine delle cose
Poiché il Transformer processa tutte le parole insieme, non conosce intrinsecamente il loro ordine. Per rimediare, a ogni embedding viene sommato un "positional encoding", un vettore che codifica la posizione del token nella sequenza.
L'educazione dell'algoritmo: come nasce un modello
Un Transformer inizia come una tabula rasa con pesi casuali. Diventa un assistente utile attraverso tre fasi chiave.
Pre-training (Pre-addestramento): la compressione della conoscenza
Il modello viene esposto a una quantità enorme di testo (web, libri, codice) con un unico obiettivo: prevedere la parola nascosta in una sequenza. In questo modo impara grammatica, fatti e ragionamento di senso comune. Alla fine di questa fase è un potente completatore di testo (Base Model), ma non un assistente.
Supervised Fine-Tuning (SFT): imparare a seguire le istruzioni
Il modello viene addestrato su dataset creati da umani, composti da coppie [Istruzione] -> [Risposta Ideale]. Impara così a comprendere le richieste e a rispondere in modo utile e conversazionale.
L'allineamento: RLHF vs Constitutional AI
Fase critica per rendere l'IA sicura e allineata ai valori umani. Due approcci principali:
RLHF (Reinforcement Learning from Human Feedback - OpenAI/Meta): Umani classificano diverse risposte generate dal modello dal migliore al peggiore. Questi dati addestrano un "Modello di Ricompensa" separato, che poi guida l'LLM a generare risposte migliori tramite apprendimento per rinforzo.
Constitutional AI (Anthropic): Al modello viene fornita una "Costituzione" (principi di sicurezza e etica). Il modello impara ad autocriticare e riscrivere le proprie risposte per conformarsi a questi principi, riducendo la necessità di supervisione umana continua.
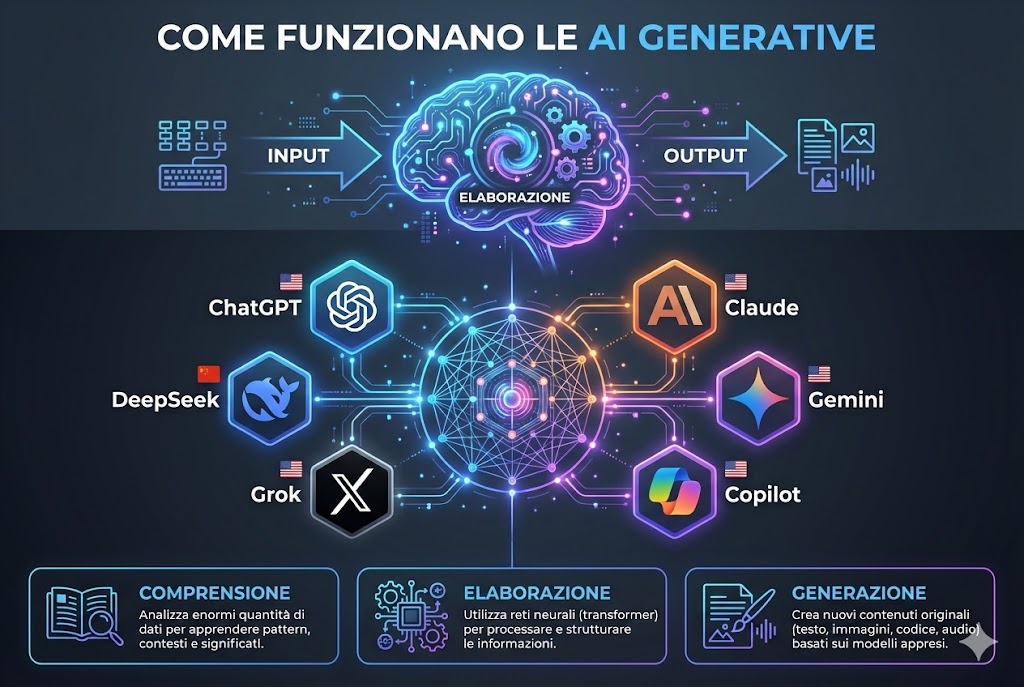
Il panorama dei giganti: analisi comparativa (2025)
Il mercato è un oligopolio dinamico. Ecco un confronto delle principali IA:
Caratteristica
ChatGPT (OpenAI)
Claude (Anthropic)
Gemini (Google)
Llama / Mistral (Open)
Punto di Forza
Ragionamento logico, Versatilità
Finestra di contesto, Sicurezza, Scrittura
Ecosistema nativo, Multimodalità
Efficienza, Privacy, Open Source
Modello di Punta
GPT-4o / o1
Claude 3.5 Sonnet / Opus
Gemini 1.5 Pro / Ultra
Llama 3.1 405B / Mistral Large
Architettura
Dense / MoE (Stimato)
Constitutional AI
Multimodale nativa (MoE)
Dense / Sparse
Allineamento
RLHF intensivo
Constitutional AI
RLHF + Dati proprietari
RLHF comunitario
ChatGPT di OpenAI: il pioniere che ha cambiato tutto
ChatGPT è sviluppato da OpenAI, un'azienda americana fondata nel 2015 con sede a San Francisco. Lanciato nel novembre 2022, ha raggiunto 100 milioni di utenti in soli due mesi, un record assoluto. Il sistema si basa sui modelli GPT (Generative Pre-trained Transformer), attualmente alla versione GPT-4.
I punti di forza di ChatGPT includono la capacità di generare testi creativi di alta qualità, dalla scrittura di codice alla composizione di poesie. Eccelle nella programmazione e nel problem solving logico. La versione Plus offre accesso a plugin per navigare sul web, analizzare dati e creare immagini con DALL-E. Il modello è particolarmente efficace nel mantenere conversazioni coerenti e nel comprendere contesti complessi.
Claude di Anthropic: l'intelligenza artificiale etica e affidabile
Claude è creato da Anthropic, azienda americana fondata nel 2021 da ex membri di OpenAI, con sede a San Francisco. Il nome richiama Claude Shannon, padre della teoria dell'informazione. Attualmente disponibile nelle versioni Opus, Sonnet e Haiku della famiglia Claude 4.5.
Le caratteristiche distintive di Claude sono l'enfasi sulla sicurezza e l'allineamento con i valori umani. Il sistema è progettato per essere particolarmente accurato nell'analisi di documenti lunghi, potendo gestire fino a 200.000 token (circa 150.000 parole). Eccelle nell'analisi critica, nel ragionamento complesso e nella scrittura di codice pulito e ben documentato. Claude tende a essere più prudente nelle risposte, ammettendo quando non è sicuro invece di inventare informazioni.
Google Gemini: l'intelligenza multimodale del gigante della ricerca
Gemini è sviluppato da Google DeepMind, divisione di Google (Alphabet Inc.), azienda americana con quartier generale a Mountain View, California. Lanciato nel dicembre 2023, rappresenta l'unificazione degli sforzi di Google nell'intelligenza artificiale, sostituendo il precedente Bard.
Il punto di forza principale di Gemini è la multimodalità nativa: è progettato fin dall'inizio per comprendere e generare testo, immagini, audio e video simultaneamente. Si integra perfettamente con l'ecosistema Google (Gmail, Docs, Drive, Maps). Eccelle nell'elaborazione di informazioni visive e nella ricerca di dati aggiornati grazie all'accesso diretto al motore di ricerca Google. Disponibile in tre versioni: Ultra per compiti complessi, Pro per uso generale e Nano per dispositivi mobili.
Microsoft Copilot: l'assistente integrato nella produttività
Microsoft Copilot è sviluppato da Microsoft Corporation, colosso americano con sede a Redmond, Washington. Lanciato nel 2023, si basa sulla tecnologia GPT-4 di OpenAI attraverso una partnership strategica, ma con ottimizzazioni specifiche di Microsoft.
La caratteristica principale è l'integrazione profonda con Microsoft 365: Word, Excel, PowerPoint, Outlook e Teams. Copilot può automatizzare compiti complessi come creare presentazioni da documenti, analizzare dati in Excel o riassumere lunghe catene di email. È disponibile gratuitamente in Windows 11 e nel browser Edge. La versione enterprise offre protezione dei dati aziendali e conformità normativa. Eccelle nell'automazione della produttività quotidiana e nella generazione di contenuti professionali.
Grok di xAI: l'intelligenza artificiale con accesso a X (Twitter)
Grok è creato da xAI, azienda americana fondata nel 2023 da Elon Musk, con l'obiettivo dichiarato di "comprendere la vera natura dell'universo". La sede è in Nevada, Stati Uniti.
Grok si distingue per il tono meno formale e più diretto, con un tocco di umorismo. Ha accesso in tempo reale ai dati di X (precedentemente Twitter), permettendo di rispondere su eventi e tendenze attuali. È progettato per essere meno censurato rispetto ai concorrenti, rispondendo anche a domande più controverse. Attualmente disponibile solo per abbonati X Premium. Eccelle nell'analisi di trend social e nella comprensione del linguaggio colloquiale e dei meme.
DeepSeek: l'emergente cinese che sfida i giganti occidentali
DeepSeek è sviluppato da DeepSeek AI, azienda cinese fondata nel 2023 con sede a Hangzhou. Rappresenta uno dei più avanzati modelli di intelligenza artificiale provenienti dalla Cina, competendo direttamente con le soluzioni occidentali.
I punti di forza includono un'architettura particolarmente efficiente dal punto di vista computazionale, che permette di ottenere prestazioni elevate con minori risorse hardware. Eccelle in compiti matematici e di ragionamento logico. Il modello è open source, permettendo a ricercatori e sviluppatori di studiarne il funzionamento e personalizzarlo. Offre ottime prestazioni nel coding e nell'analisi di codice complesso. Particolarmente competitivo in termini di costi per le aziende.
Come scegliere l'intelligenza artificiale giusta per le proprie esigenze
La scelta dipende dall'uso specifico che si intende fare. Per creatività e versatilità generale, ChatGPT resta il leader. Per analisi approfondite di documenti e ragionamento complesso, Claude è insuperabile. Se lavorate nell'ecosistema Google, Gemini offre un'integrazione perfetta. Per la produttività aziendale con Microsoft 365, Copilot è la scelta naturale. Grok è ideale per chi segue trend social e vuole risposte meno filtrate. DeepSeek rappresenta un'ottima alternativa open source per sviluppatori e ricercatori.
Tutti questi sistemi continuano a evolversi rapidamente, con nuove versioni e capacità che vengono rilasciate regolarmente. La competizione tra queste piattaforme sta spingendo l'innovazione a ritmi mai visti prima, portando benefici a tutti gli utenti.
Il futuro delle intelligenze artificiali generative promette sviluppi ancora più sorprendenti: dalla comprensione sempre più sofisticata del contesto alla capacità di ragionamento multimodale avanzato. Comprendere come funzionano questi strumenti oggi ci prepara a sfruttarli al meglio domani, in un mondo dove l'intelligenza artificiale diventerà sempre più integrata nella nostra vita quotidiana.
Oltre la chat: il principio del ragionamento avanzato
Chain of Thought (CoT): mostrare il lavoro
Forzare il modello a scrivere i passaggi logici intermedi ("mostrare il lavoro") inserisce questi passi nel contesto, permettendogli di prestare "attenzione" ai propri calcoli precedenti. Questo riduce drasticamente gli errori (allucinazioni) in compiti complessi.
Dal Sistema 1 al Sistema 2
Gli LLM standard operano come il "Sistema 1" di Kahneman (pensiero veloce e intuitivo). Modelli come OpenAI o1 stanno simulando il "Sistema 2" (pensiero lento e analitico), spendendo tempo di calcolo per esplorare, verificare e correggere internamente prima di rispondere.
Futuro: agenti, AGI e la società del 2030
Agentic AI: l'IA che "fa" cose
Il prossimo passo sono agenti autonomi che, con permesso, potranno agire nel mondo digitale: prenotare voli, gestire email, organizzare task interagendo con API e strumenti esterni.
AGI e le leggi di scala
L'obiettivo finale è l'Intelligenza Artificiale Generale (AGI), capace di apprendere ed eseguire qualsiasi compito intellettuale umano. Le "Scaling Laws" suggeriscono progressi costanti con più dati e potenza, ma ostacoli come il consumo energetico e la scarsità di dati di alta qualità potrebbero rallentare la corsa.
Le intelligenze artificiali generative rappresentano il trionfo dell'approccio empirico. Abbiamo costruito macchine che deducono le regole del mondo osservando dati, passando dalla semplice predizione statistica al sofisticato ragionamento via Transformer e Chain of Thought. Non sono coscienti, ma sono specchi potenti della conoscenza umana. Comprenderne il funzionamento reale è essenziale per navigare il futuro che stanno plasmando.